
There are many facets to the sustainability issue for a database that currently lives more or less on a grant to grant cycle. But as we are engaging in the schema design (deciding which data needs to be further captured) and user experience (don’t forget that people who contribute are also users – very important ones), I’ll focus in this post on how these issues impact on sustainability.
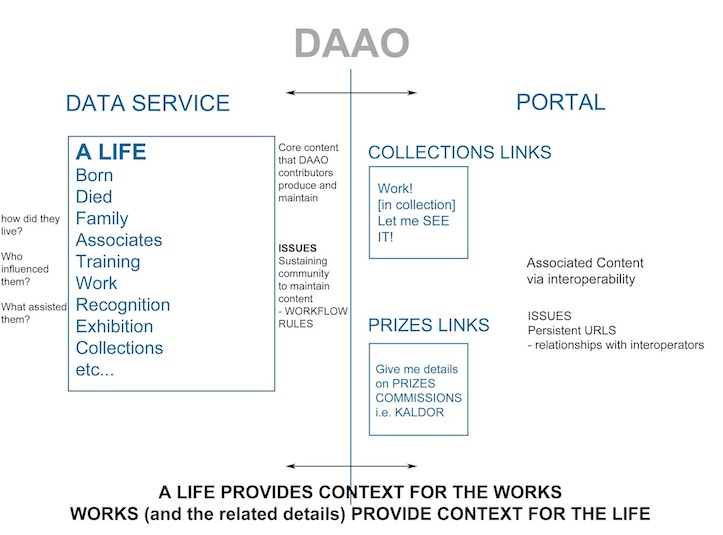
How can ensure the sustainability of the data? Who will provide us with the data we need and who will maintain it and keep it up- to-date. The DAAO currently operates mainly as Data Service. That is to say, the DAAO’s contributors create content for the DAAO around the core business of ‘biography’. Our data describes the ‘life’ of an artist or designer. It provides information on where they were born, how they were trained, what work did they produce, it also provides information that can be used to ask questions like ‘who influenced them?’ (ie associates) , ‘who supported them?’ (ie institutions, curators, awards). As we move through the consultation and research process, researchers in the art and design history area have identified areas in which in would be useful to have more extensive capture of certain data- in particular more information about ‘works’ ( whether they be design objects or art works (of all manner of material/immaterial, and/or temporally and locationally distributed complexity) as well as more information on ‘exhibitionary spaces’ and who curates, funds and manages them. The question then arises, who will input the information? Who is doing research in these areas? Or are there existing databses that already have much of the information we seek and could we leverage existing data collections by other people/institutions rather than re-entering information that is already maintained by other people?
For those who are already contributors to the DAAO, you will be well-aware of the large commitment it can take to complete a biographical record to the DAAO. If you are contributing a bio of almost any artist or designer, you may have as many as 20 exhibitions to enter, maybe a similar amounts of works ( often more if one is to be truly comprehensive), in addition to birth, date, training, associates, language, family etc fields to fill in. It is daunting and has been identified as such by many potential contributors. Our job is then to balance the differing demands on the database. The way that we do this falls roughly into three major considerations.
1) Think about data entry: be very judicious about what additional fields we want to capture. We do not want to put contributors off because we are asking too much of them. Contributing to the DAAO should be made easy and if possible pleasurable and satisfying. We want people to feel a benefit for their efforts.
2) Think about design. How can we make data entry easier for people to contribute- so the task doesn’t appear so daunting. We can modify the process- so that some fields auto-fill as the author is writing a bio. Or we can change the layout and presentation of data entry forms so they are easier to complete. We can also make it easier for people to just do small adjustments on records. Ie they can just add small bits of info to existing records to make them more complete.
3) Think about interoperability. Do other data sets exist that already have detailed information about entities ( such as works, exhibitions and prizes) that we could interoperate with. So we can just put in relatively minimal information on an award and then provide a link to a source database which has extensive information ( ie the AGNSW prizes database). In other words, we could operate as a portal to other information and thus expand our content by aggregating data from other sources into our website.
So in a sense the issue of data capture becomes distributed. We want to produce a database that provides meaningful and accurate results for researchers. So how do we build on the strengths we already have and what new relationships can we develop with other scholarly researchers to extend our reach in a way that is realistic and sustainable?
This diagram below is a rough drawing of what the DAAO is now and it also gestures to how we might grow. The DAAO is, in principle, a data service and a portal. Data service refers to the data that we upload and maintain. That is, we are responsible for the data being correct and up-to-date). Portal refers to the data that we ‘interoperate with’- this can take the form of providing links to other data ( ie collections data from institutional repositories). We also need to be judicious about who we decide to interoperate with. For instance, we need to ensure that the information that we are linking to is correct and up-to-date. The last thing we want to provide multiple links out to sites that no longer exist or are unable to maintain their own data.
To further complicate matters, we also need to make sure that we have sufficient data captured in some fields so that we can interoperate according to the metadata standards that enable data sets to be exposed to each other on the internet. This is also vital to our sustainability.
Fortunately, we have highly skilled pool of people who are helping us tackle the task. In addition to our CIs and PIs and other disciplinary experts who have been throwing all kinds of curly content capture problems at us so we can test the robustness of our schema, we also have the expertise of many data librarians/managers across the GLAM ( Galleries, Musuems, Archives and Museum) sector who are generously providing advice and support to the DAAO’s Data Manager, Jo ( shout out in particular to Ingrid Mason from the Powerhouse Museum!). Moreover our User Experience designers ( the House of Laudaunum) have worked on many similar projects and are also providing valuable input into the technical issues of how we achieve our goals.
We are also fortunate that much of the DAAO’s original schema is pretty sound and is capable of capturing much of what we need with only a few modifications and extensions and clearer instructions on how to fill out the fields correctly. Much of the work is actually about mapping the relationship between the data fields, so that when we search we can actually produce meaningful search results. By mid-november we should have a ‘test’ database online which will test some of the key relationships between data that we are currently working on. We will send you an email when it it online, so we can get your feedback.